BLOG
Data Lake Best Practices: Prevent Your Data Lake from Turning into a Data Swamp

A data lake isn’t just a cheaper way to store data. When properly crafted, data lakes can be a centralized source of truth offering team members valuable flexibility to examine information that impacts business decisions.
Raw data is like crude oil, which demands a meticulous refinement process to distill more usable products, like gasoline. Similarly, raw data requires complex processing to leverage insights, take action, and measure outcomes.
As the volume of available data and variety of its sources continue to grow, more and more companies find themselves sitting on the data equivalent of a reservoir of crude oil with no way to extract the true market value. Where traditional data warehouses act as gas stations, data lakes are the oil refineries.
Data warehouses are becoming increasingly insufficient for handling this scale of a business’s raw data. They require the information to already be pre-processed like gasoline. Data lakes, however, allow for the storage of structured or unstructured data from any number of sources, such as business and mobile applications, IoT devices, social media, and more.
What does a well-maintained data lake look like? What are the best practices at the forefront of implementation, and how do they impact your bottom line?
Explaining Data Lakes – and How they Transform Business
Data lakes are a centralized storage entity for any information that can be mined for insights. This includes structured data (gas), unstructured data (oil), and any other information from relational databases-text files, reports, videos, etc. A well-maintained data lake has the real potential to transform your business by offering a singular source for your company’s data-in whatever form it may be-that enables your business analysts and data science team to mine information in a scalable, sustainable way.
Data lakes are often designed in a cloud-hosted environment like Amazon Web Services, Microsoft Azure, or Google Cloud Platform. The concept leverages big data practices with clear financial benefits-it’s at least twenty times cheaper to store, access, and analyze in a data lake compared to using a traditional data warehouse. Part of the power behind data lakes is the design structure, or schema, which does not need to be written until after the data has been loaded (unlike a data warehouse, which must be designed prior to implementation). The information is stored exactly as it is entered, regardless of structure, and is not separated into silos for different data sources. This inherently decreases the overall time to insight for an organization’s analytics. It also provides increased speed when accessing quality data, helping to inform business-critical activities. Taking advantage of scalable architecture, low-cost storage, and high-performance computing power can allow companies to shift focus from data collection to data processing in real-time. Instead of spending hours mining scattered deposits, you have one source to pull from that ultimately frees up valuable human resources to create stronger partnerships across teams. A data lake frees up your data science team to explore potential business-critical insights that could inform new business models in the future.
Hayward is a great example of a company that is rich in data but struggled to bridge the gap across their sources previous to working with Very. Their marketing data lived in Salesforce’s CRM but their mobile app data lived in its own separate relational database. They needed an environment where unification was possible. Together, we created Hayward’s data lake, built on the Google Cloud Platform. By piping both sources, it’s now possible to link registration, warranty, and other customer information to the configuration, status, and activity of the pools themselves. Thanks to Very, Hayward can now create more intentional content for their targeted audiences, adding an additional layer of refinement to their marketing campaigns and so much more.
Best Practices from the Experts
Similar to a stagnant pool of water polluting over time, a data lake that is not held to the right standards is difficult to maintain and susceptible to flooding from bad data and poor design. So, what do you do to set up a system that’s primed for business transformation and growth? Very recommends the following actions to help prevent your data lake from turning into a swamp.
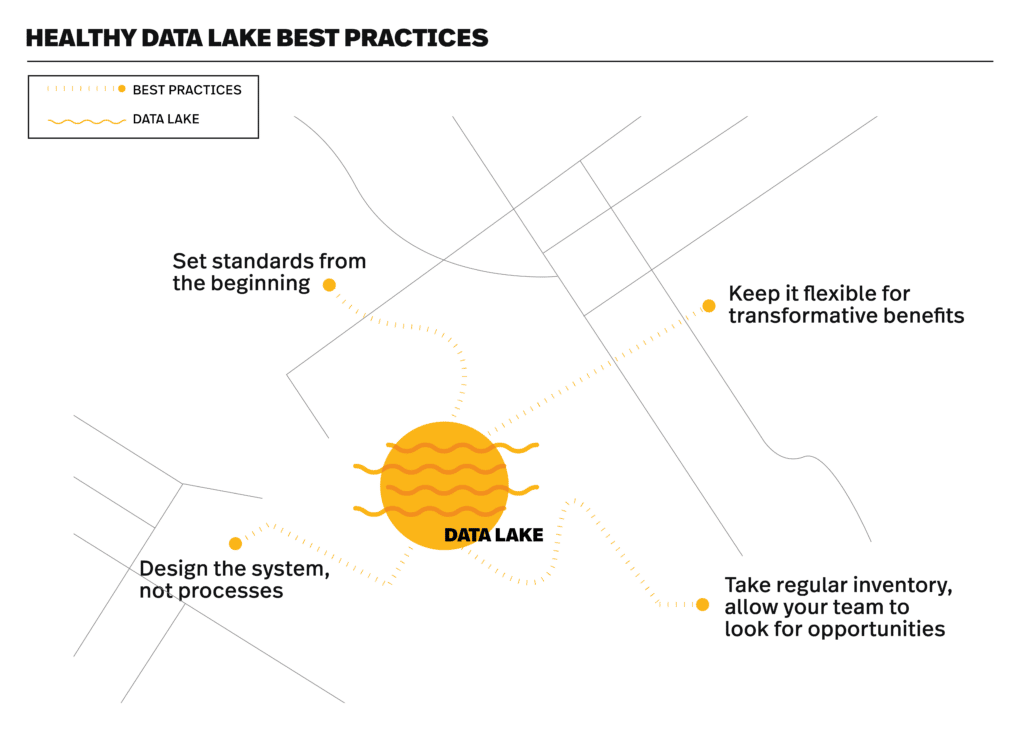
1. Set standards from the beginning
The backbone of a healthy data lake is dynamic infrastructure. This includes creating scalable and automated pipelines, exploiting cloud resources for optimization, and monitoring connections and system performance. Start by making intentional data-design decisions during project planning. Define standards and practices-these should not be compromised at any point through implementation-and allow your ecosystem to handle edge cases and the potential for new data sources. Remember: it’s all about freeing up your data science team from tending to an overtaxed data system so they can focus on what’s truly important.
2. Maintain flexibility for transformative benefits
A healthy data lake requires an environment that can handle dynamic inputs. This extends beyond just varying sources, sizes, and types of data to the structure of the data itself-and how it is ingested into storage.
For example, creating an event-driven pipeline not only simplifies automation, it also grants source flexibility in terms of file delivery schedules. Setting up a pipeline with trigger events for automation, based on when a file hits a storage location, alleviates concerns whenever the files come in. It’s vital that you support your data science team’s fluidity around rapid testing, failing, and learning to refine the analytics that power your company’s key strategic initiatives, which ultimately drive new, innovative opportunities.
3. Design the system, not the processes
A common misconception is that problem-specific solutions may seem faster at the onset. One advantage of data lakes is that they’re not tied or centralized around any one source, where a hyper-specialized solution for individual data sources suffers from resistance to implementing change and requires its own error management. Additionally, when a highly specific process is introduced, it likely won’t add value to the system as a whole, as it cannot be utilized elsewhere.
Architecting your data lake with modular processes and source-independent pipelines will save time in the long run by allowing for faster development times and simplifying new feature implementations. Efficiency over time is the name of the game.
4. Take regular inventory to find opportunities
Event-driven pipelines are great for cloud automation, but the tradeoff is that they require post-event monitoring to understand what files are received, by whom, on which dates, etc. One way to monitor and share this information is to set up a summary dashboard of data reports from varying sources. This, paired with alerting mechanisms for processing errors, creates a notification system for those instances when part of the data lake is not functioning as anticipated-while ensuring errors and exceptions do not go undetected. The ability to track and handle this activity becomes increasingly important as more information is accrued.
Proper inventory initiatives create stronger environments; the kind where your data science team feels supported in exploring additional metrics opportunities that may inform stronger business decisions in the future.
Summary
Data lakes revolutionize business intelligence by paving the way for team members to examine sources of clean data faster and more efficiently. A clean data lake speeds decision-making, reduces toil, and increases business model ingenuity. A few simple best practices can prevent future headaches and keep your data streamlined and humming.
Want to learn more?
If you’re ready to harness the power of IoT, our team of knowledgeable, experienced developers can help. We handle every aspect of your IoT projects, from design and prototyping to engineering and programming.